Die translytische Datenverarbeitung - kurz: Translytik - ist eine Mischform der beiden grundlegenden Methoden der Datenverarbeitung: der transaktionalen Datenverarbeitung und der analytischen Datenverarbeitung*. Während früher eine klare Trennung zwischen den beiden Methoden möglich war, gibt es heute immer mehr Anwendungsfälle, in denen sie ineinander übergehen und somit ein translytisches System bilden, das eine translytische Unternehmensarchitektur erfordert. Im Folgenden möchte ich die Merkmale und Herausforderungen der Translytik im Unternehmensumfeld aufzeigen.
Transaktionale Datenverarbeitung
Die transaktionale Datenverarbeitung (auch OLTP für Online-Transaction-Processing) ist eine Methode der Datenverarbeitung, die sicherstellt, dass eine Abfolge von Operationen, die als “Transaktion” zusammengefasst werden, entweder vollständig ausgeführt oder, falls ein Fehler auftritt, alle rückgängig gemacht werden, um den ursprünglichen Zustand wiederherzustellen. Dies ist wichtig, um die Integrität der Daten in einer Datenbank zu gewährleisten.
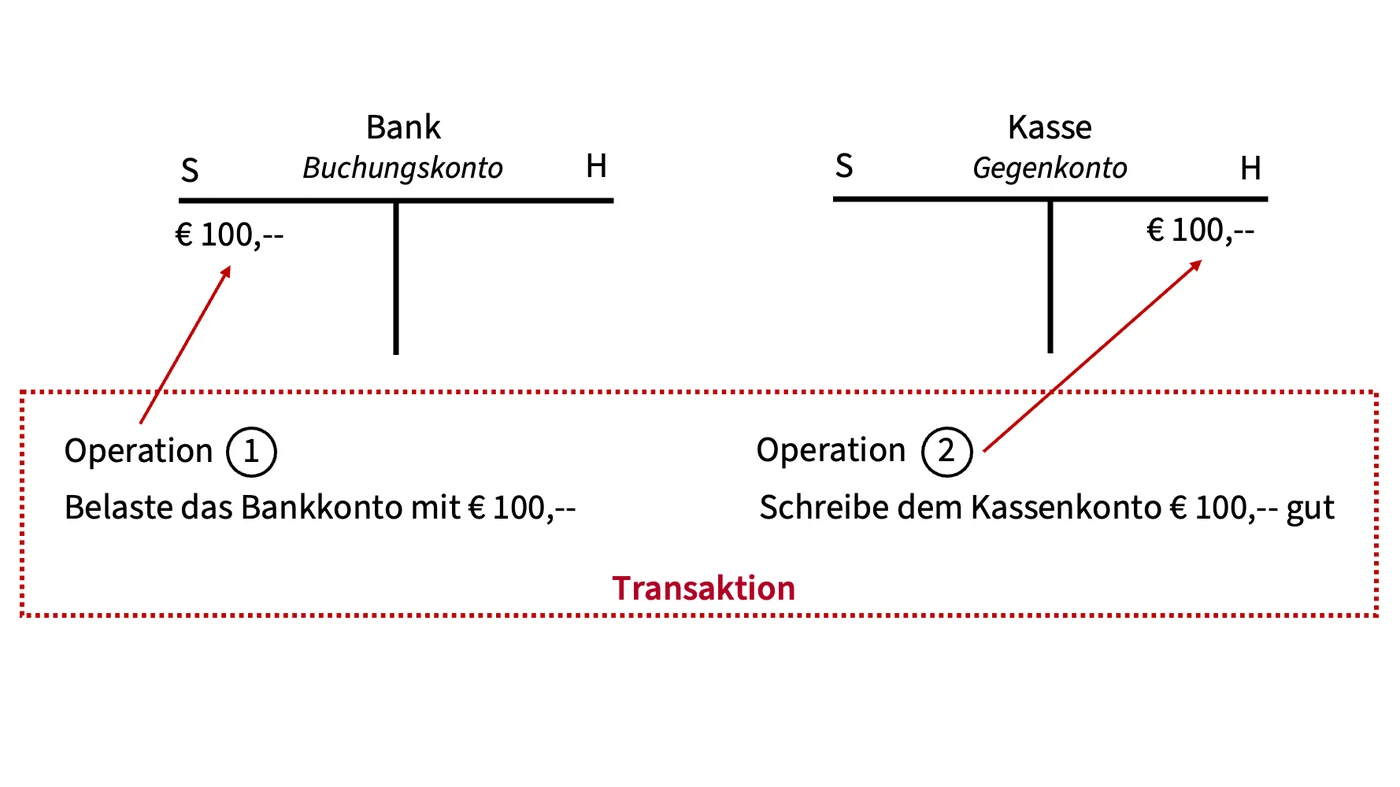 Beispiel für eine Transaktion: Buchung von Bank an Kasse in der doppelten Buchführung
Beispiel für eine Transaktion: Buchung von Bank an Kasse in der doppelten Buchführung
Das gezeigte Beispiel einer Buchung über € 100,– vom Bankkonto an das Kassenkonto in der doppelten Buchführung zeigt eine klassische Transaktion. In der ersten Operation muss das Bankkonto um den Betrag belastet werden (Soll-Buchung). In der zweiten Operation muss der Betrag dem Kassenkonto gutgeschrieben werden (Haben-Buchung). Sollte nur eine der beiden Operationen ausgeführt werden, ist die Buchung nicht korrekt. Daher werden die beiden Operationen in eine Transaktion zusammengefasst. Diese Transaktion wird vollständig oder gar nicht ausgeführt.
Die transaktionale Datenverarbeitung ist für eine korrekte Buchführung unerlässlich. Sie kommt aber auch in vielen anderen Geschäftsprozessen zum Einsatz.
Technisch werden für die transaktionale Datenverarbeitung vor allem zeilenorientierte, relationale Datenbanksysteme eingesetzt. Das bedeutet, dass die Datensätze in der Datenbank als Zeilen von Tabellen zusammengefasst und gespeichert werden. Dadurch ist es möglich, sehr effizient auf die einzelnen Zeilen zuzugreifen und die Operationen auszuführen. Zu anderen Datensätzen, die ebenfalls in Zeilen gespeichert sind, bestehen Verbindungen - die Relationen.
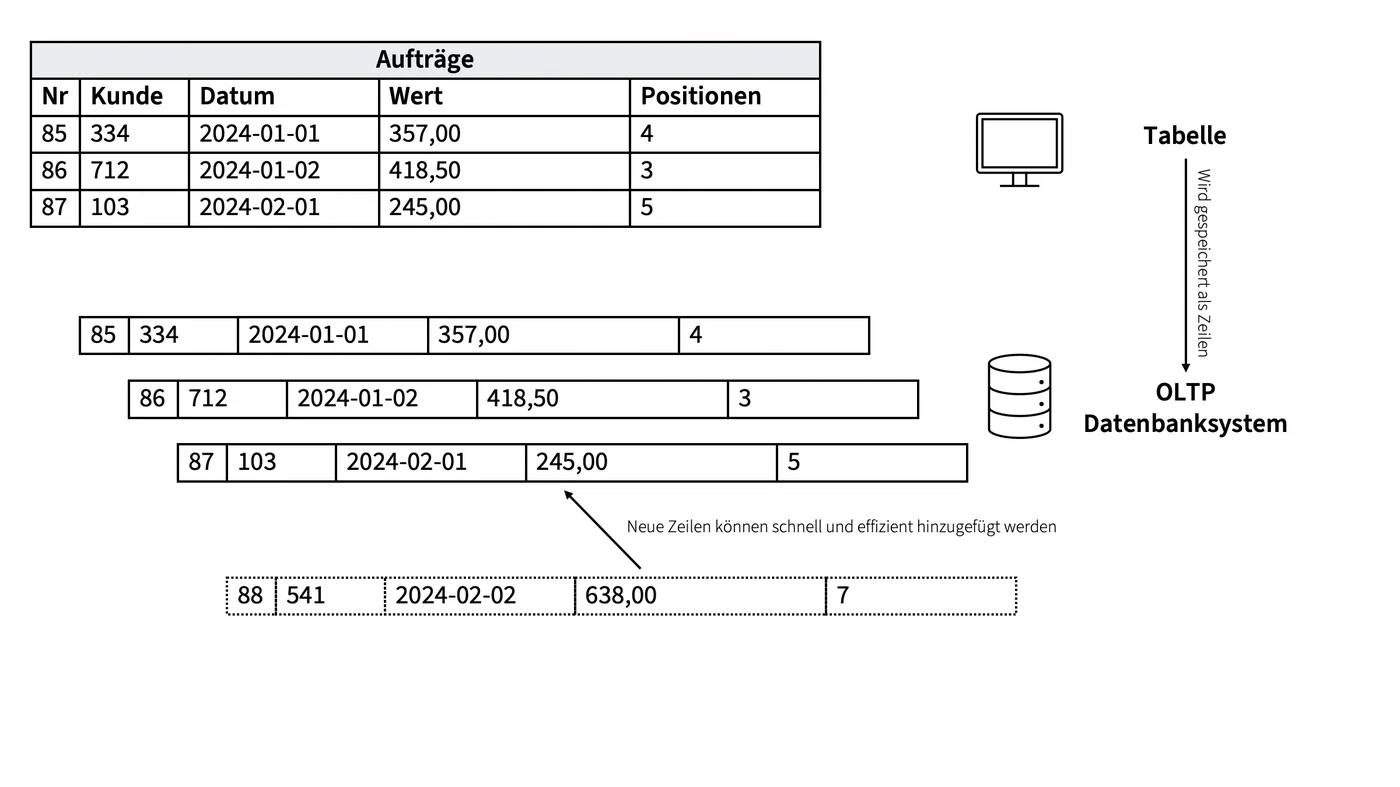 Speicherung der Daten in einer zeilenorientierten Datenbank
Speicherung der Daten in einer zeilenorientierten Datenbank
Transaktionen in Form von Schreiboperationen auf einen Datensatz können in einer solchen Datenbank sehr schnell durchgeführt werden. Beispiele für solche Transaktionen können neben den oben genannten Buchungen auch das Anlegen und Ausführen von Aufträgen oder die Benutzerverwaltung sein.
Transaktionale Datenbanken folgen in der Regel dem ACID-Paradigma. ACID steht für Atomicity, Consistency, Isolation, Durability. Es bedeutet, dass eine OLTP-Datenbank sicherstellt, dass die Transaktionen atomar sind, d.h. dass sie, wie oben gefordert, ganz oder gar nicht ausgeführt werden. Darüber hinaus muss das Datenbanksystem aber auch konsistent sein, d.h. nach Beendigung einer Transaktion alle Integritätsbedingungen erfüllen. Die Isolation verlangt, dass sich parallel ausgeführte Transaktionen nicht gegenseitig beeinflussen. Und die Dauerhaftigkeit (Durability) verlangt, dass nach erfolgreichem Abschluss einer Transaktion die Daten dauerhaft in der Datenbank gespeichert bleiben, auch wenn danach ein Systemfehler auftreten sollte.
Analytische Datenverarbeitung
Unter analytischer Datenverarbeitung (auch: OLAP für Online Analytical Processing) versteht man die Verarbeitung großer Datenmengen mit dem Ziel, Erkenntnisse und Einsichten zu gewinnen, die für die Entscheidungsfindung in Unternehmen, Organisationen und anderen Bereichen nützlich sind. Bei der analytischen Datenverarbeitung werden in der Regel Techniken wie Data Mining, maschinelles Lernen und Statistik eingesetzt, um Muster in den Daten zu erkennen und zu analysieren.
Die Ergebnisse der analytischen Datenverarbeitung können in verschiedenen Formen präsentiert werden, z. B. als Berichte, Diagramme oder Dashboards. Sie können auch verwendet werden, um Vorhersagen über zukünftige Ereignisse zu treffen oder Handlungsempfehlungen zu generieren.
Im Gegensatz zur transaktionalen Datenverarbeitung, die darauf ausgelegt ist, Ereignisse in Echtzeit zu verarbeiten und zu verwalten, ist die analytische Datenverarbeitung eher darauf ausgelegt, die Vergangenheit zu analysieren und Erkenntnisse für die Zukunft zu gewinnen.
Technisch werden für die analytische Datenverarbeitung vor allem spaltenorientierte oder auch multidimensionale Datenbanksysteme eingesetzt. Das bedeutet, dass die Spalten einer Tabelle gemeinsam gespeichert werden. Dies ermöglicht schnelle Auswertungen über die Spalten, wie z.B. die Berechnung von Summen oder Durchschnittswerten. Während bei einer zeilenorientierten Datenbank alle Zeilen gelesen werden müssen, um den Durchschnitt eines Feldes zu berechnen, genügt bei einer spaltenorientierten Datenbank das Lesen einer einzigen Spalte.
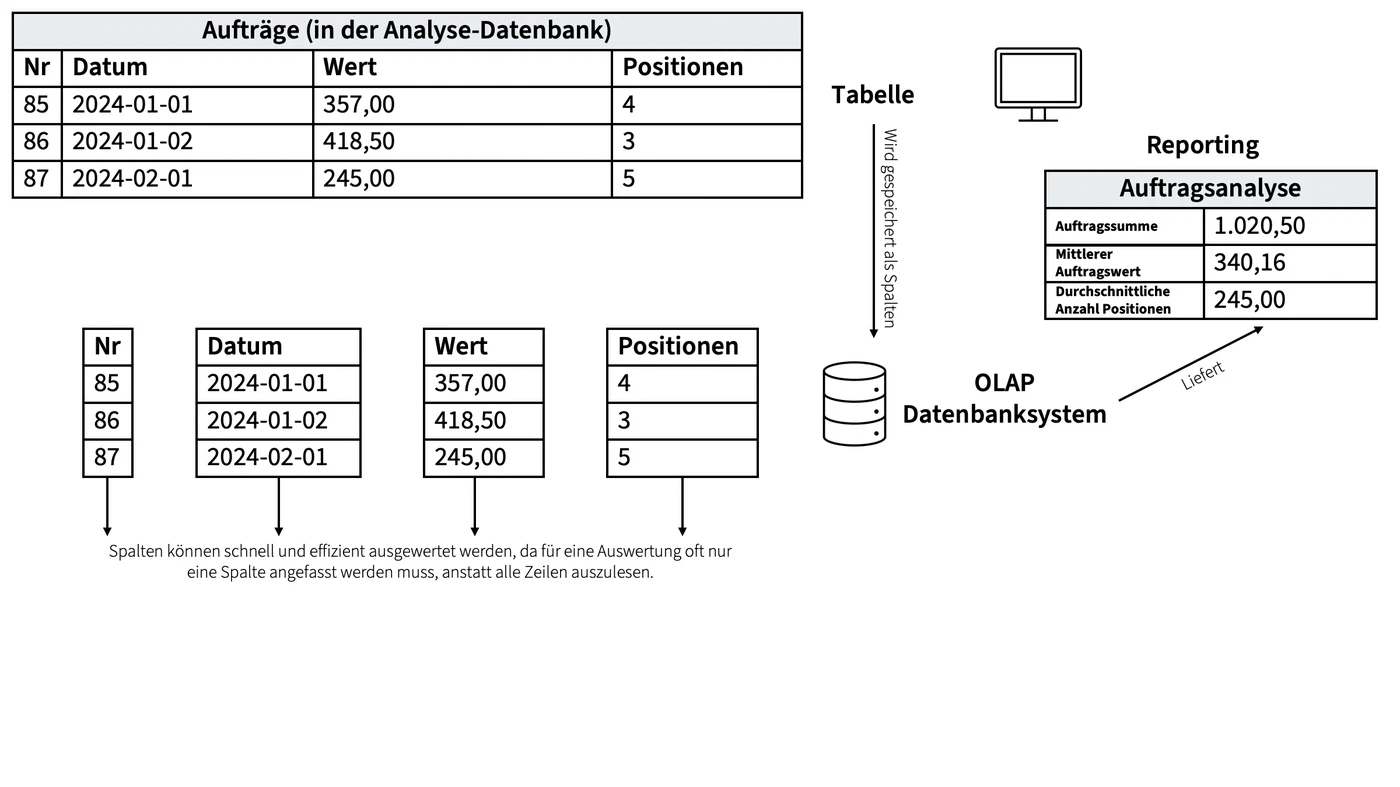 Speicherung der Daten in einer spaltenorientierten Datenbank
Speicherung der Daten in einer spaltenorientierten Datenbank
Weitere Formen der Datenverarbeitung
Die beiden hier betrachteten Formen der Datenverarbeitung und -speicherung in zeilen- oder spaltenorientierten Datenbanken sind nicht die einzigen, die es gibt. Sie spielen jedoch die größte Rolle in Geschäftssystemen zur Abwicklung von Geschäftsvorgängen und zum Treffen von Geschäftsentscheidungen. Daten können nicht nur transaktional oder analytisch verarbeitet werden, sondern z.B. auch in Stapeln. Und sie können nicht nur als Zeilen in relationalen Datenbanken oder als Spalten in analytischen Datenbanken gespeichert werden, sondern auch in Key/Value Stores, Document Stores oder als Graphen. Auf diese Formen der Speicherung und Verarbeitung möchte ich in diesem Artikel jedoch nicht näher eingehen.
Transaktional vs Analytisch
Wie eingangs beschrieben und in der folgenden Tabelle zusammengefasst, widersprechen sich die beiden Modelle der transaktionalen und analytischen Datenverarbeitung in wesentlichen Punkten: Zugriffsmuster, Zugriffsfrequenz, Zeitverhalten, Verfügbarkeit und Speicherung.
| Merkmal | Transaktional | Analytisch |
|---|---|---|
| Zugriffsmuster | Viele Inserts und Updates, wenige Selects | Wenige Inserts und Updates; Fokus auf Selects |
| Zugriffsfrequenz | Hohe Anzahl kurzer Statements | Niedrige Anzahl langlaufender Statements |
| Zeitverhalten | Nahe Echtzeit | Periodisch |
| Verfügbarkeit | Hohe Verfügbarkeit der Datenbank erforderlich | Hochverfügbarkeit der Datenbank nicht notwendig |
| Speicherung | Zeilenorientiert | Spaltenorientiert |
Widersprüchliche Merkmale der transaktionalen und analytischen Datenverarbeitung
Diese widersprüchlichen Eigenschaften spielen eine umso größere Rolle, je höher die Last auf einem Datenbanksystem ist. Auf einem kleinen ERP-System, das im normalen Geschäftsbetrieb wenig ausgelastet ist und nur von Montag bis Freitag von 7 bis 20 Uhr benötigt wird, können trotz relationaler, zeilenorientierter Speicherung auch noch nachts Analysen durchgeführt werden. Die gegensätzlichen Anforderungen der Datenverarbeitungsmethoden können in diesem Fall durch stärkere Hardware ausgeglichen werden. Dies ist aus Sicht der Informatik nicht optimal, kann aber betriebswirtschaftlich sinnvoll sein.
Wird jedoch ein großes Warenwirtschaftssystem für einen Online-Shop rund um die Uhr benötigt und sollen viele Kaufvorgänge in Echtzeit abgewickelt werden, so ist es nicht empfehlenswert, auf diesem System auch die Analyse der Verkäufe durchzuführen. Umgekehrt ist es nicht sinnvoll, Geschäftsvorfälle, die rund um die Uhr in Echtzeit ablaufen müssen, auf einem spaltenorientierten Data Warehouse laufen zu lassen. Durch die ungeeignete Art der Speicherung erzeugen die Geschäftsvorfälle eine ungünstige Last und das Data Warehouse muss mit aufwändigen Maßnahmen hochverfügbar gemacht werden.
Es gibt Datenbanksysteme, die sowohl zeilen- als auch spaltenorientiert speichern können. Sie sollten dies aber nicht in derselben Instanz tun. Denn selbst wenn sie es können, erzeugen sie die oben genannten Widersprüche innerhalb derselben Instanz.
Translytische Datenverarbeitung
Translytische Datenverarbeitung liegt vor, wenn transaktionale Vorgänge während ihrer Laufzeit in Geschäftsprozessen mit analytischen Systemen ausgewertet und die Ergebnisse in Echtzeit in die Geschäftsprozesse zurückgespielt und dort verwendet werden.
Translytische Datenverarbeitung muss die oben dargestellten widersprüchlichen Anforderungen in Einklang bringen. Während es bei kleineren Unternehmen und IT-Landschaften vielleicht noch möglich ist, eine “one size fits all”-Datenbank zu finden, muss bei Hochlast- und Hochleistungssystemen sehr genau darauf geachtet werden, welche Datenbanksysteme und weitere Komponenten eingesetzt werden. Im Hochleistungsbereich kann man die algorithmischen Herausforderungen nicht mit Hardware erschlagen, wie es bei kleineren Systemen noch möglich ist. Man kann auch nicht den “kleinsten gemeinsamen Nenner” finden, denn eine Datenbank ist entweder zeilenorientiert und transaktional oder spaltenorientiert und analytisch. Im Sinne eines exklusiven oder. Auch wenn das zugrunde liegende Datenbankmanagementsystem beide Varianten beherrscht. Die einzelnen Tabellen jedoch nicht.
Algorithmus schlägt Hardware
Embedded Translytics
In heutigen Geschäftsanwendungen werden beide Formen der Datenverarbeitung bereits unter dem Schlagwort Embedded Analytics kombiniert. Embedded Analytics bezieht sich dabei auf die Integration von Analysefunktionen direkt in Geschäftsanwendungen, so dass Anwender in ihrer gewohnten Arbeitsumgebung auf Datenanalysen zugreifen können, ohne auf separate BI-Tools wechseln zu müssen.
Eine solche Anwendung kann ohne großen Aufwand um KI-Anwendungsfälle erweitert werden. Der Charakter der Anwendung ändert sich dadurch nicht. Werden jedoch die Teile einer Anwendung, die bisher nur Analyse- und Reportingfunktionen bereitstellen, so verändert, dass die Ergebnisse in die Geschäftsprozesse zurückfließen, entsteht Embedded Translytics.
Die großen Herausforderungen liegen dabei einerseits beim Entwickler einer solchen Anwendung, der die beiden widersprüchlichen Formen der Datenverarbeitung unter einen Hut bringen muss. Und zum anderen beim Betreiber einer solchen Anwendung. Eine translytische Anwendung ist im Betrieb komplexer als eine “einfache” transaktionale Anwendung.
Eine Embedded Translytics-Anwendung hat jedoch keine großen Auswirkungen auf die Unternehmensarchitektur. Soll nicht nur eine einzelne Anwendung von translytischer Datenverarbeitung profitieren, sondern eine ganze Systemlandschaft, dann ist eine translytische Unternehmensarchitektur notwendig.
Translytische Unternehmensarchitektur
Die translytische Unternehmensarchitektur betrachtet nicht nur eine einzelne Anwendung. Sie ist eine Strategie für die Kombination von transaktionaler und analytischer Datenverarbeitung auf der Ebene der Unternehmensarchitektur.
Moderne Unternehmen benötigen sowohl leistungsfähige Geschäftsanwendungen und -prozesse als auch leistungsfähige analytische Systeme. Neben dem klassischen Einsatz für das betriebswirtschaftliche und strategische Berichtswesen werden Analysen heute auch für maschinelles Lernen und als Datengrundlage für KI-Systeme genutzt. Wenn die Ergebnisse der Analysesysteme in Echtzeit in die transaktionalen Geschäftsprozesse zurückfließen und diese beeinflussen, entsteht eine translytische Unternehmensarchitektur.
Ein anschauliches Beispiel für eine translytische Architektur ist der Geschäftsprozess eines guten Online-Shops: Der Kunde legt einen Artikel in den Warenkorb (= transaktionaler Prozess). Im Hintergrund analysiert ein Analysesystem das Kaufverhalten des Kunden auf Basis seiner Stammdaten, seiner bisherigen Einkäufe, seines Verhaltens im Online-Shop und des Verhaltens anderer Kunden. All diese Daten können aus unterschiedlichen Anwendungen stammen. In Echtzeit wird das Ergebnis der Analyse - eine Kaufempfehlung im Sinne von: andere Kunden, die diesen Artikel gekauft haben, haben auch folgende Artikel gekauft - in den Geschäftsprozess zurückgespielt.
Ein anderes Beispiel wäre ein Betrugserkennungssystem einer Bank, das in Echtzeit analysiert, ob eine Transaktion betrügerisch sein könnte. Dieses System muss Transaktionen aus verschiedenen Quellen in Echtzeit verarbeiten, um schnelle Entscheidungen treffen zu können. Es muss aber auch in der Lage sein, Muster in den Transaktionsdaten zu erkennen und zu analysieren, um betrügerische Aktivitäten zu identifizieren.
Eine translytische Architektur muss den Spagat zwischen den beiden - eigentlich widersprüchlichen - Anforderungen der oben genannten transaktionalen und analytischen Datenverarbeitung schaffen.
Architekturmuster für translytische Enterprise Architekturen
Bei diesem Muster wird die IT-Landschaft eines Unternehmens, die bisher nur aus transaktionalen Anwendungen und analytischen Auswertungen bestand, um eine translytische Plattform erweitert:
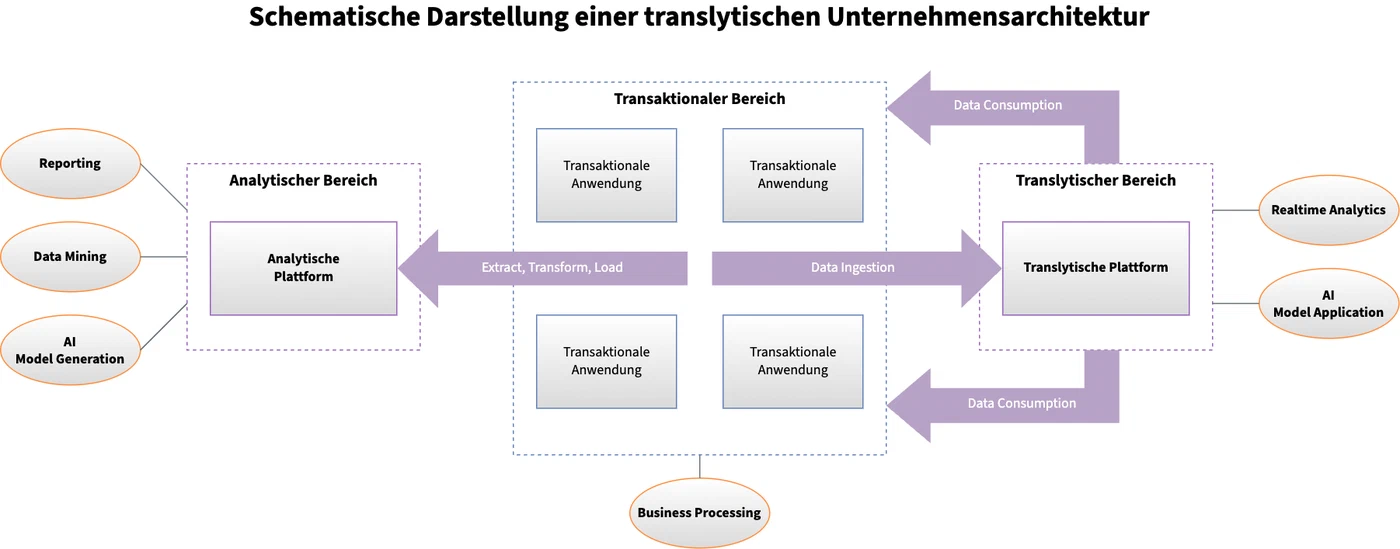 Eine IT-Landschaft mit zentraler translytischer Plattform
Eine IT-Landschaft mit zentraler translytischer Plattform
Die bestehende Analytische Plattform (links im Bild) kann wie bisher für zeitintensive Prozesse, deren Laufzeit nicht sicher kalkuliert werden kann, wie z.B. Data Exploration, Mining oder individuelles Reporting genutzt werden. Diese Plattform kann zusätzlich um den Anwendungsfall der AI Model Generation erweitert werden.
Auf der anderen Seite steht die translytische Plattform, die technisch ebenfalls aus einem OLAP-Datenbanksystem und zugehörigen Logikkomponenten besteht. Auf diesem System werden jedoch nur die Analysen durchgeführt, deren Ergebnisse in die transaktionalen Bereiche zurückfließen müssen. Dabei sollte es sich in erster Linie um standardisierte, getestete Analyseaussagen handeln - nicht um individuelle Abfragen wie im analytischen Bereich. Dadurch wird eine gewisse Vorhersagbarkeit in der Ausführungszeit der Statements geschaffen. Außerdem sollten in diesem Bereich die KI-Modelle laufen, die im analytischen Bereich trainiert wurden.
Die Geschäftsanwendungen im transaktionalen Bereich sollten um Sicherungen erweitert werden. Diese müssen sicherstellen, dass Geschäftsprozesse auch dann weiterlaufen, wenn Ergebnisse aus dem translytischen Bereich auf sich warten lassen. Je nach Geschäftsprozess kann auf einen solchen Fall unterschiedlich reagiert werden. Beispielsweise kann der Geschäftsprozess in einer minimalen Form weiterlaufen (“graceful degradation”) oder in einem dafür vorgesehenen Zustand enden. Auf keinen Fall sollte sich eine Geschäftsanwendung blauäugig darauf verlassen, dass die benötigten Ergebnisse aus dem translytischen Bereich rechtzeitig eintreffen. Denn dies könnte dazu führen, dass Geschäftsprozesse zum Stillstand kommen, abbrechen und sich im schlimmsten Fall gegenseitig behindern.
Der Vorteil dieses Musters ist, dass alle Geschäftsanwendungen ohne große Aufwände von Translytik und KI profitieren können.
Fazit
Die translytische Datenverarbeitung macht weder die transaktionale noch die analytische Datenverarbeitung überflüssig. Sie erweitert beide. Im obigen Beispiel einer Bank kann die Betrugserkennung auf Basis der translytischen Plattform in das Transaktionssystem der Bank integriert werden. Das Data Warehouse der Bank wird dadurch nicht überflüssig, da die klassischen analytischen Geschäftsprozesse wie Statistiken über Kundenzahlen oder Geldflüsse weiterhin durchgeführt werden müssen.
Mit dem vorgeschlagenen Modell für eine translytische Unternehmensarchitektur kann ein Unternehmen schnell und umfassend von fortgeschrittenen Algorithmen und KI-Systemen profitieren, ohne die gesamte transaktionale Landschaft neu aufbauen zu müssen.